Youtube channel playlist generation using topic modeling
The purpose of this project is to create play lists of the videos in a youtube channel. I didn’t find a free server to support youtube query thus this app is not online. The code can be found on github.
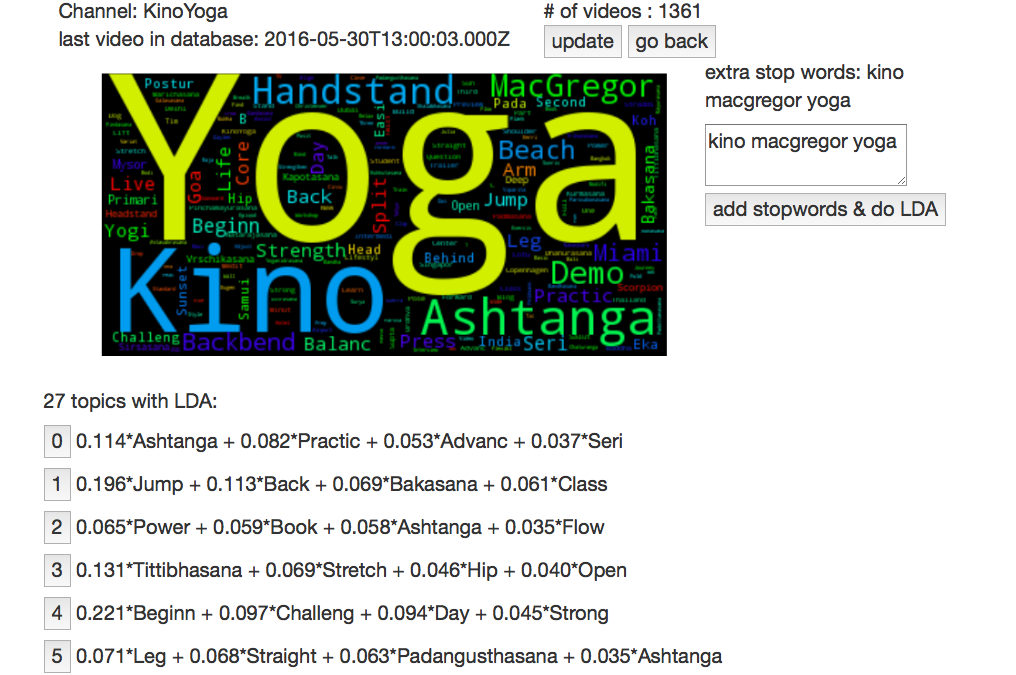
Here I used a simple bag-of-words (BOW) model for topic modeling. For preprocessing, I removed certain stop words and also turned words to their stem form. The relevant codes are as follows.
from gensim import corpora
import gensim
from nltk.stem.porter import PorterStemmer
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
porter = PorterStemmer()
from nltk.corpus import stopwords
stop = set(stopwords.words('english'))
import re
from functools import partial
if channel.get('stopwords'):
extra_w = [x.lower() for x in channel['stopwords'].split()]
stopw = stop.union(extra_w)
else:
stopw = stop
new_tokenizer = partial(tokenize_text, stopw)
titles = [new_tokenizer(v['title']) for v in videos]
Gensim makes it very easy to perform latent Dirichlet analysis. The relevant codes are as follows.
def do_LDA(titles,num_topics):
dictionary = corpora.Dictionary(titles)
corpus = [dictionary.doc2bow(title) for title in titles]
threshold = 1/num_topics
ldamodel = gensim.models.ldamodel.LdaModel(corpus,
num_topics=num_topics, id2word = dictionary,
passes=20, minimum_probability=threshold)
# assign topics
lda_corpus = [max(x,key=lambda y:y[1])
for x in ldamodel[corpus] ]
return ldamodel.show_topics(num_topics=num_topics,
num_words=4), lda_corpus
Share it on → 

