Milestone 5 of the gita project: miscellaneous topics
This is the fifth and last milestone where we make further enhancements such as repo groups and bash shell auto completion. I will also talk about marketing an open source project.
The other posts in this series are
- overview
- milestone 1: basic CLI
- milestone 2: git integration
- milestone 3: git delegation
- milestone 4: speedup
- milestone 5: miscellaneous topics
v0.4.1: repo groups
Often times a project consists of several repos and it’s important to keep them on the same branch and timeline. It is then helpful to define a repo group, which syntactically behaves like a repo but semantically delegates to the group members. For example, instead of calling
gita pull repo1 repo2 repo3
we can call
gita pull my-group
where the group my-group consists of the three repos.
Another useful call is
gita super my-group co 20-3-release
which checks out the branch 20-3-release for all repos in my-group.
If you have followed the previous milestones, you will find its implementation straightforward.
v0.4.2: bash auto completion
If you use Linux terminal, you probably hit the tab key often to automatically complete file paths, commands, environment variables, etc. You may also notice that tab completion doesn’t work for all commands. (Indeed it doesn’t work for our work-in-progress gita clone yet). In this commit we will make it happen. Specifically, we will auto complete for
- gita sub-commands
- registered repo names
- file paths for
gita add
For example, if we type gita and hit tab, all the sub-commands
will be displayed, something like this
$ gita
add diff group ll merge pull reflog reset show stash tag
br difftool info log mergetool push remote rm show-branch stat ungroup
clean fetch last ls patch rebase rename shortlog st super whatchanged
If we type gita p and hit tab, we will see all the sub-commands that start
with p, something like this
$ gita p
patch pull push
If we type gita pus and then hit tab, push will be completed since it is
already the only match.
As an example for the second auto-completion feature, if we type gita pull
then hit tab, all registered repos will show up.
To make it work, we need to define the auto completion behaviors in a bash script,
say .gita-completion.bash.
Inside it, we will have a line
complete -F _gita_completions gita
Here complete is the magic word that registers the function _gita_completions
for auto-completing the gita command.
I won’t show details of this _gita_completions here.
Hopefully you can figure it out using the pointers below.
You may want to read
GNU doc: Programmable Completion Builtins
for more options for complete. Besides -F for function, the other common ones
are
-Wfor a list of fixed words-Afor special actions
Typically you will source .gita-completion.bash in the .bashrc so that every
new terminal register the auto-completion behaviors for gita.
To get the lists of the sub-commands and repos, my current strategies are
- sub-commands: parse the
gita -houtput usingsed - repos: use the output of
gita ls
The other building blocks for the _gita_completions function are
COMPREPLY: an array variable for the return of_gita_completionscompgen: a utility command that generates word list for auto completion$COMP_WORDS: the equivalent ofargv, which contains a list of words in the current command line$COMP_CWORD: the word index in$COMP_WORDSwhere the cursor is at. For example,COMP_WORDS[1]is the word immediately after the command (say, aftergita)
The following two blog articles give a good summary for bash auto completion.
- Bash completion tutorial: this alone may be enough
- Adding Bash Completion To a Python Script
If you never write shell script before, try this book

If you want a cheat sheet, check out this link.
marketing an open source project
I am by no means an expert in marketing, and this section is more of my story
on promoting the gita project. Please let me know if you have any suggestions
for better results.
The main features of gita were finished in early 2018
(see original blog post here), which roughly
amount to milestone 3.
After one year’s passing, it got 5 stars on GitHub: 3 from my coworkers,
1 from myself, and one from a stranger (I wonder how he found the project).
One day it suddenly occurred to me that I should post it on hacker news. And this is what happened
- @1am posted on Hacker News Show
- @6:30am got up with 115 stars and 3 issues
- @1am second day: 274 stars, 1 more issue, and 3 pull requests
I also took a screenshot of the GitHub analytics on the second day.
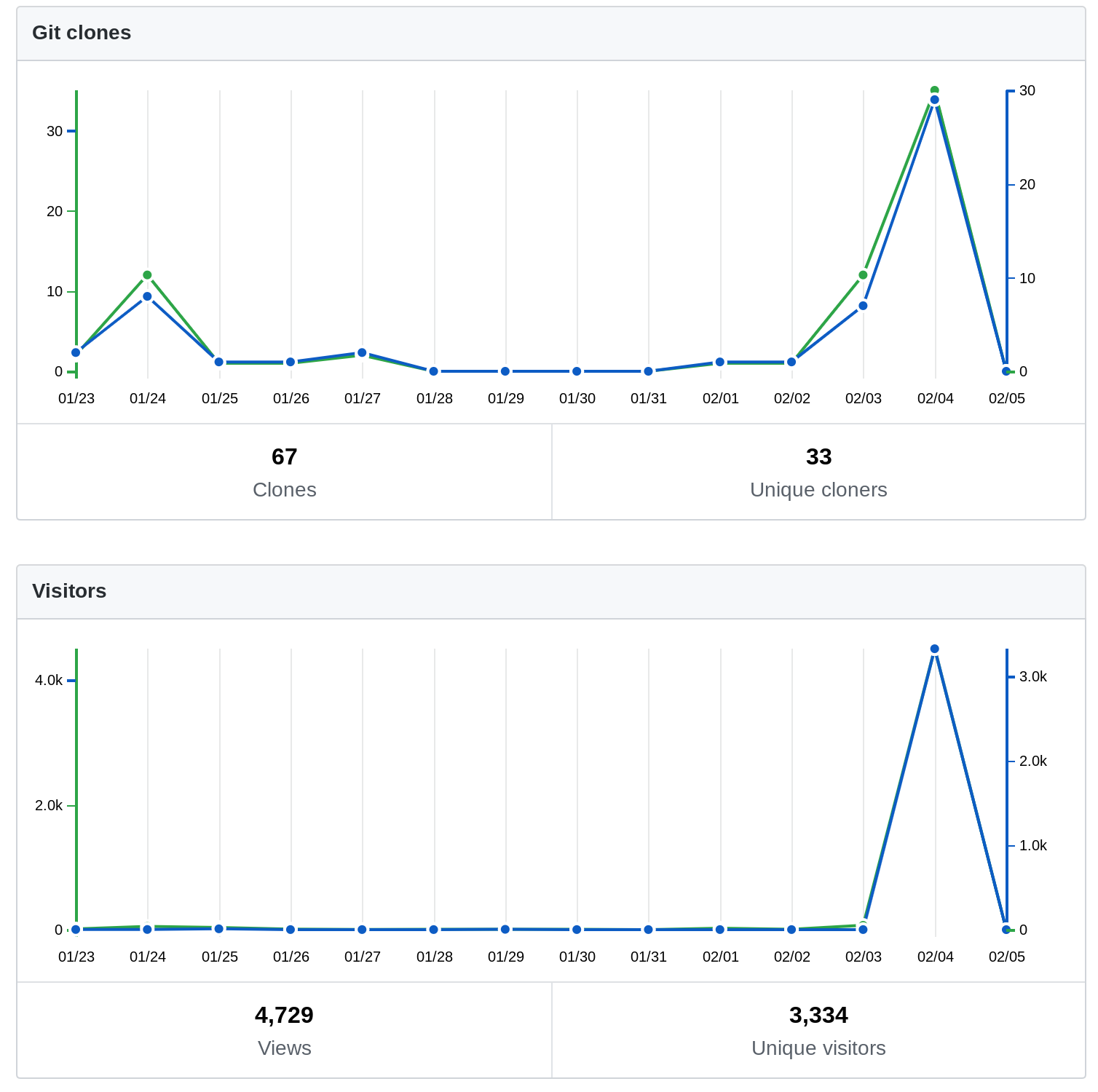
It then went on the HN front page and also the GitHub trending page for that week. The star/visit ratio is about 1:10, and the star/download ratio is about 1:2.
It tells me that other people find it useful too, and I should keep increasing its exposure on other platforms. Here is an incomplete list of them, roughly ranked by the effectiveness in bringing in traffic.
- hacker news
- gank.io
- Product Hunt
- awesome cli apps
- reddit
- /programming
- /python
- /git
- /commandline
- open hub
- mention gita in my stackoverflow answers about multiple repo management, and asyncio usage
- Hello github
- Terminals Are Sexy
- awesome python applications
- github daily
Besides them, I also got traffic from other people’s recommendations such as Ruan Yifeng’s blog.
That’s basically all I did for marketing, probably too preliminary. If you are completely clueless like me, maybe the following articles will be useful.
- Open Source Guides
- How to promote your open source project
- How to promote your GitHub project
- How to get up to 3500+ GitHub stars in one week — and why that’s important
- How to Spread The Word About Your Code
- Stackoverflow open source advertising 2019
One annoying thing is that GitHub only saves analytics data for two weeks. You may be interested in repo-analytics written by Tim Qian.
parting words
So this is the end. I hope you have learned something from these posts. I also hope you will start to create something on GitHub soon. Remember to
- solve a real problem
- write great
README.md - add other credentials
- test coverage
- stars
- issues/pull requests
- contributors
And finally, make sure to promote it!


